




Hello, buddies! Watching movies is a great way to reduce your stress. Also, we have to select suitable movies you should watch. Like when you are tired of coding and debugging all day, watching a scientific movie may harm your brain. So, here we are going to make an emotion-based movie recommendation, using Python!
Presquities
IMDb offers all the movies for all genres. Therefore the movie titles can be scraped from the IMDb list to recommend to the user. So here, we have to perform scraping as the is no IMDb API.
- An IDE
- Python Basics
- And the modules! We will be using only 3 modules,
- BeautifulSoup
- lxml
pip install BeautifulSoup
The scraper is written in Python and uses lxml for parsing the web pages. BeautifulSoup is used for pulling data out of HTML and XML files.
Coding Time 😎
First of all, we have to import the libraries as follows,
from bs4 import BeautifulSoup as SOUP
import re
import requests as HTTP
Before get into scraping, we have to match the genres of the movies and the emotion,
Sad – Drama
Disgust – Musical
Anger – Family
Anticipation – Thriller
Fear – Sport
Enjoyment – Thriller
Trust – Western
Surprise – Film-Noir
Cool, now we know. Next, we have to make the main function for scraping from imdb.com
# Main Function for scraping
def main(emotion):
# IMDb Url for Drama genre of
# movie against emotion Sad
if(emotion == "Sad"):
urlhere = 'http://www.imdb.com/search/title?genres=drama&title_type=feature&sort=moviemeter, asc'
# IMDb Url for Musical genre of
# movie against emotion Disgust
elif(emotion == "Disgust"):
urlhere = 'http://www.imdb.com/search/title?genres=musical&title_type=feature&sort=moviemeter, asc'
# IMDb Url for Family genre of
# movie against emotion Anger
elif(emotion == "Anger"):
urlhere = 'http://www.imdb.com/search/title?genres=family&title_type=feature&sort=moviemeter, asc'
# IMDb Url for Thriller genre of
# movie against emotion Anticipation
elif(emotion == "Anticipation"):
urlhere = 'http://www.imdb.com/search/title?genres=thriller&title_type=feature&sort=moviemeter, asc'
# IMDb Url for Sport genre of
# movie against emotion Fear
elif(emotion == "Fear"):
urlhere = 'http://www.imdb.com/search/title?genres=sport&title_type=feature&sort=moviemeter, asc'
# IMDb Url for Thriller genre of
# movie against emotion Enjoyment
elif(emotion == "Enjoyment"):
urlhere = 'http://www.imdb.com/search/title?genres=thriller&title_type=feature&sort=moviemeter, asc'
# IMDb Url for Western genre of
# movie against emotion Trust
elif(emotion == "Trust"):
urlhere = 'http://www.imdb.com/search/title?genres=western&title_type=feature&sort=moviemeter, asc'
# IMDb Url for Film_noir genre of
# movie against emotion Surprise
elif(emotion == "Surprise"):
urlhere = 'http://www.imdb.com/search/title?genres=film_noir&title_type=feature&sort=moviemeter, asc'
Fine, these are only the URLs. Still, we didn't do the scraping part.
# HTTP request to get the data of
# the whole page
response = HTTP.get(urlhere)
data = response.text
# Parsing the data using
# BeautifulSoup
soup = SOUP(data, "lxml")
# Extract movie titles from the
# data using regex
title = soup.find_all("a", attrs = {"href" : re.compile(r'\/title\/tt+\d*\/')})
return title
Great! We have come half of our way. Next, we have to make the driver function.
if __name__ == '__main__':
emotion = input("Enter the emotion: ")
a = main(emotion)
count = 0
if(emotion == "disgust" or emotion == "anger"
or emotion=="surprise"):
for i in a:
tmp = str(i).split('>;')
if(len(tmp) == 3):
print(tmp[1][:-3])
if(count > 13):
break
count += 1
else:
for i in a:
tmp = str(i).split('>')
if(len(tmp) == 3):
print(tmp[1][:-3])
if(count > 11):
break
count+=1
It's super easy to understand this code, let's define it.
First, we take input for the type of emotion from the user and then, assign it into the variable a
After that, we make a for loop for splitting each line of the IMDb to scrape the data.
And if the tmp is equal to 3, we print the first element(movie) and slice the last 3. And next, we print it!
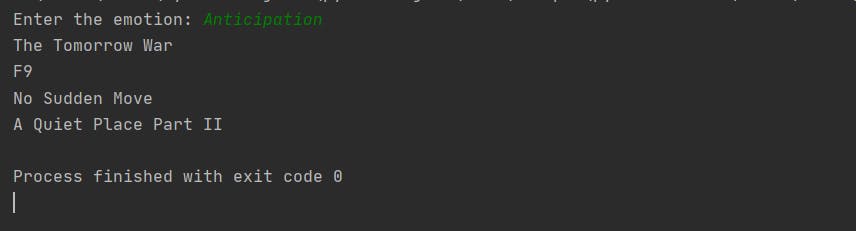
So, the result will be,
Drop a star if you find it useful! ⭐
That's it, buddies! Thanks for reading and happy coding!